Las grandes cantidades de datos que se almacenan en la actualidad requieren de un sistema de gestión que nos permita administrarlo de manera eficiente y rápida. A lo largo de la historia de las bases de datos existieron diversos modelos que se enfocaban en resolver estos problemas, algunos cumplieron su papel en su momento quedando obsoletos o simplemente reemplazados por otros mejorados. Algunos de aquellas épocas todavía se implementan en ciertos sistemas infórmaticos combinados con modelos actuales. En este post hablaremos un poco de ellos, específicamente de los modelos jerárquico y de red. También hablaremos de un nuevo modelo que está surgiendo, que todavía no está estandarizado pero que tiene una gran utilidad: el modelo no relacional o comunmente conocido NoSQL.
1. El modelo Jerárquico
Este modelo se remonta a la década de los 60’s. Fue implementado en la SGBD IMS(Information Management System) y desarrollado por la North American Aviation e IBM para el proyecto de alunizaje Apollo y que fue la dominante en el mercado por muchos años.
1.1 Estructura de datos jerárquica
Utiliza el árbol como su estructura de datos básica. Un árbol es un grafo dirigido que consiste en una jerarquía de nodos, con un solo nodo, llamado raíz, en el nivel más alto. En este modelo una base de datos consiste en una colección de instancias de un solo diagrama de estructura de árbol en el que cada nodo contiene uno o más campos de datos que representan atributos que describen una entidad. Todo el árbol puede ser una descripción de una sola entidad, o bien usarse diferentes segmentos dentro de un árbol para representar distintas entidades, pero relacionadas. Como ejemplo creamos un diagrama de estructura de datos para un árbol que representa la facutad de una universidad. En esta estructura se eligió hacer FACULTY el nodo o segmento raíz, con sus campos FACID, FACNAME, DEPT y RANK. CLASS se representa como un hijo de FACULTY, el cual muestra que hay una relación 1 a muchos entre cada registro FACULTY y sus registros CLASS asociados. Es posible visualizar esta relación al decir que los registros CLASS no existen independientemente, sino que están anidados dentro de los registros FACULTY. Note que se omite el campo FACID del segmento CLASS. Puesto que la clase está dentro de un registro faculty particular, no hay necesidad de repetir el FACID. Su valor se “hereda” del padre. También se tiene el registro STUDENT como un segmento del árbol, y se representa como un hijo de CLASS. Al segmento STUDENT se agrega GRADE pues no hay ambigüedad acerca del curso al cual se refiere la calificación del estudiante.

Figura 1. Representación jerárquica de la base de datos UNIVERSiTY.
En el siguiente esquema se muestra una instancia del árbol FACULTY-CLASS-STUDENT. En una instancia del árbol, un nodo hijo puede aparecer cero, una o muchas veces, aun cuando ocurra exactamente una vez en el diagrama de estructura de árbol. En este ejemplo, para un registro FACULTY dado, puede haber tantos segmentos CLASS como se necesite, y cada uno de éstos puede tener un número arbitrario de segmentos STUDENT.

Figura 2. Una instancia del árbol UNIVERSITY.
En el modelo jerárquico, a cada tipo de segmento se le asigna un código tipo único,de acuerdo con su posición en el diagrama de estructura de árbol. Los códigos tipo están determinados por el recorrido preordenado de la estructura del árbol, de modo que la raíz tiene código tipo 1, su hijo más a la izquierda tiene código tipo 2, el hijo más a la izquierda de dicho hijo tiene código tipo 3, etc. Para el ejemplo de la figura C.1, FACULTY tiene código tipo 1, CLASS tiene código tipo 2 y STUDENT tiene código tipo 3.
Esta instancia se puede representar en almacenamiento al usar recorrido preordenado para crear una representación plana del registro, como se muestra en la figura C.3. En dicha representación, se ve que el segmento FACULTY aparece primero, seguido por el primer segmento CLASS, que es seguido por el primer STUDENT en dicha clase.

Figura 3. Representación de un árbol.
En almacenamiento, el código tipo, junto con otra información de cabecera, se almacena como prefijo para el segmento, pero no lo ve el usuario. Esto permite al DBMS distinguir segmentos uno de otro. Cada nueva instancia de árbol comienza con un código tipo 1.
1.2 Aplicaciones
El modelo de bases jerárquica todavía se utiliza en algunas aplicaciones, por ejemplo para los servidores que necesitan mantener los datos por largos periodos de tiempo pero sin modificarlos. También se usan conjunto con otras bases de datos simples que contiene pocos registros necesita menos tiempo para programar.
2. El modelo de red
El modelo de red es también un modelo de bases de datos antiguo, se usó a principios de la década de 1960 en uno de los primeros sistemas de gestión de base de datos, Integrated Data Store, creado por Charles Bachman en General Electric. Otro de los primeros DBMS que usó el modelo de red fue el IDMS (Integrated Database Management System).
Una base de datos en red consiste en cualquier número de tipos de registros mominados cuyas estructuras se describen por completo en el esquema. Un registro tiene cualquier número de ítems de datos o campos, que son las unidades de datos nominadas más pequeñas. Cada ítem de datos tiene un tipo de datos específico asociado con él en el esquema. Los ítems de datos se pueden agrupar en agregados de datos, que pueden estar anidados. Los diagramas de estructura de datos en red, como se muestran en la figura 4, se pueden usar para representar estructuras de bases de datos. Este diagrama corresponde a un gráfico de red en el que los nodos se sustituyeron por rectángulos que representan registros y vínculos sustituidos por flechas que conectan los rectángulos. Los rectángulos se pueden subdividir para mostrar ítems de datos. Los vínculos por lo general son relaciones unidireccionales 1 a muchos, pero también se permiten relaciones 1 a 1 y bidireccionales. La base de la flecha viene desde el nodo propietario y la punta de la flecha apunta hacia el nodo miembro o dependiente en cada relación.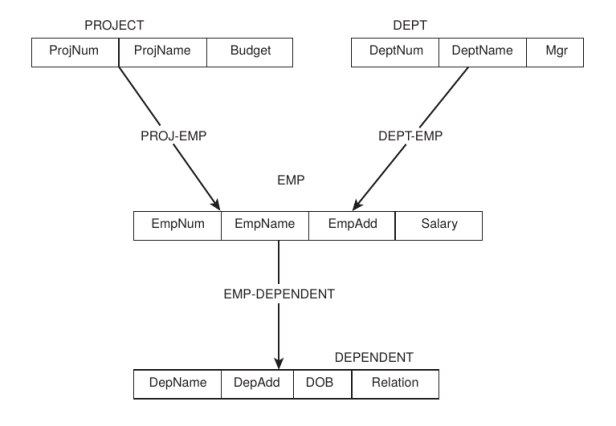
Figura 4. Un diagrama de estructura de datos de red.
2.1 El lenguaje de definición de datos (LDD)
2.1.1 El esquema
Un esquema tiene cuatro secciones principales, a saber: la sección esquema, que nombra al
esquema; la sección área, que identifica las áreas de almacenamiento y da otra información
física; la sección registro, que proporciona una descripción completa de cada estructura de
registro con todos sus ítems de datos y detalles de ubicación de registro, y la sección conjunto, que identifica a todos los conjuntos, los tipos propietario y miembro para cada uno, y otros detalles como el ordenamiento.
2.1.2 El subesquema
El subesquema es una descripción de la visión externa de un usuario particular o conjunto
de usuarios. Proporciona independencia de datos al permitir que algunos ítems difieran del esquema. Del subesquema se pueden omitir áreas, registros, conjuntos e ítems de datos del
esquema. Los ítems de datos, registros y conjuntos se pueden renombrar.
2.2 El lenguaje de manipulación de datos (LMD)
El DML es un lenguaje procedural que requiere que el usuario esté familiarizado con
la estructura de la base de datos. Existen muchas opciones disponibles y el programador
habilidoso puede usarlos para navegar en la base de datos de manera muy eficiente.
2.2.1 Comandos DML
Los principales comandos DML DBTG y sus funciones son los siguientes:
■ OPEN: abre área(s) para procesamiento
■ CLOSE: cierra área(s) cuando el procesamiento está completo
■ FIND: encuentra la ubicación de un registro de base de datos
■ GET: lleva el registro encontrado anteriormente al área de trabajo
■ MODIFY: almacena los cambios a un registro actualizado en el área de trabajo
■ ERASE: borra un registro de la base de datos
■ STORE: agrega un nuevo registro a la base de datos
■ CONNECT: coloca un nuevo miembro en una ocurrencia de conjunto
■ DISCONNECT: remueve un miembro de una ocurrencia de conjunto
■ RECONNECT: mueve un miembro de una ocurrencia de conjunto a otro
3. Bases de datos NoSQL
NoSQL (“not only SQL”) es un término utilizado para describir un subconjunto de bases de datos que difiere en varios modos de bases de datos tradicionales (RDBMS).
Presentan las siguientes características:
• No requieren esquemas de información fijas (no tienen esquemas).
• No permiten JOINs.
• No intentan garantizar ACID (Atomicity – Consistency – Isolation – Durability).
• Escalan horizontalmente.
Tanto las bases de datos NoSQL como las relacionales son tipos de almacenamiento estructurado; la principal diferencia radica en cómo guardan los datos, mientras que en una base de datos de modelo relacional tendríamos que partir la información en diferentes tablas y luego usar un lenguaje de programación en el lado del servidor para transformar estos datos en objetos de la vida real; en NoSQL, simplemente guardas NoSQL es libre de esquemas, tú no diseñas tus tablas y su estructura por adelantado.
3.1.1 Apache Cassandra
Cassandra es un sistema de código abierto distribuido de gestión de base de datos diseñado para manejar grandes cantidades de datos a través de muchos servidores de conveniencia, proporcionando alta disponibilidad sin ningún punto único de fallo; también ofrece soporte robusto para múltiples centros de datos, con la replicación asincrónica sin necesidad de un servidor maestro, que permiten operaciones de baja latencia para todos los clientes.
El modelo de datos de Cassandra consiste en particionar las filas, que son reorganizadas en tablas . Las claves primarias de cada tabla tiene un primer componente que es la clave de partición. Dentro de una partición, las filas son agrupadas por las columnas restantes de la clave. Las demás columnas pueden ser indexadas por separado de la clave primaria.
Las tablas se pueden crear, eliminar y alterar en tiempo de ejecución sin bloquear actualizaciones y consultas.
Cassandra no soporta joins o subqueries, sino que enfatiza en la desnormalización a través de características como colecciones.
Con respecto al LMD posee su propio lenguaje llamado CQL (Cassandra Query Language), que tienen una sintaxis similar a SQL aunque con muchas menos funcionalidades. Este lenguaje incluye sintaxis SELECT, INSERT, UPDATE, DELETE, TRUNCATE, CREATE, DROP, etc. El lenguaje completo y detallado sen encuentra aquí.
Con respecto al modelo de datos Cassandra es esencialmente un híbrido entre un modelo Clave-Valor y una base de datos Tabular (Orientado a columnas).La familia de columnas (llamada “Tabla” desde CQL3) se asemeja a una tabla en un RDBMS. Estas contienen filas y columnas. Cada fila tiene múltiples columnas, cada una de estas tiene a su vez un nombre, un valor y un timestamp. A diferencia de una tabla en un RDBMS, diferentes filas en una misma familia de columnas, no tiene por que compartir el mismo conjunto de columnas, y además, una columna puede ser añadida a una o a múltiples filas en cualquier momento. Cada clave en Cassandra, corresponde a un valor que es a su vez un objeto. Cada clave tiene valores como columnas, y las columnas son agrupadas en sets que son llamados familias de columnas. Así, cada clave identifica una fila con un número variable de elementos. Estas familias de columnas, pueden ser consideradas como tablas. Una tabla en Cassandra es un mapa multi-dimensional distribuido, indexado por una clave. Además, las aplicaciones pueden especificar el orden de las columnas dentro de una Súper Columna, o una Familia de Columnas Simples.
3.1.2 Aplicaciones
Debido a la gran cantidad de tipos de bases de datos no relacionales, las aplicaciones son diversas, ya que permiten manipular datos simples hasta estructuras de datos. Son comunmente utilizados con bases de datos relacionales como por ejemplo Facebook que tiene una arquitectura híbrida con Memcached y MySQL junto a un OLTP (envío de mensajes al Wall), y Cassandra (NoSQL) para la búsqueda en la bandeja de entrada; o como LinkedIn que comenzó sólo con un RDBMS, pero desarrolló su propia BBDD NoSQL (Voldemort).
